Metadata
 Metadata, often referred to as “data about data,” is an essential component of Research Data Management (RDM). It provides the critical information needed to identify, describe, and contextualize research data. By ensuring data is Findable, Accessible, Interoperable, and Reusable (FAIR), metadata plays a pivotal role in enabling researchers and external users to understand data’s structure, context, and purpose. This, in turn, facilitates its discovery, reuse, and integration into future research.
Metadata, often referred to as “data about data,” is an essential component of Research Data Management (RDM). It provides the critical information needed to identify, describe, and contextualize research data. By ensuring data is Findable, Accessible, Interoperable, and Reusable (FAIR), metadata plays a pivotal role in enabling researchers and external users to understand data’s structure, context, and purpose. This, in turn, facilitates its discovery, reuse, and integration into future research.
Far from being just a descriptive tool, metadata serves as a foundation for data sharing, collaboration, and long-term preservation. As research generates ever-growing volumes of data, effective metadata management has become indispensable for institutions, funding bodies, and individual researchers striving to maximize the value and impact of their data. Properly designed metadata ensures that research outputs are not only accessible today but remain meaningful and usable in the years to come.
In this chapter, you can expect to learn about:
- the fundamental role of metadata in RDM and its alignment with FAIR principles;
- the different types of metadata, including descriptive, structural, administrative, and their specialized subtypes;
- best practices for creating and managing metadata, along with emerging tools and technologies;
- common challenges in metadata management and strategies to address them;
- future trends and innovations, such as automation, semantic metadata, and enhanced interoperability.
By the end of this chapter, you will have a comprehensive understanding of metadata’s importance in research data management. You will also gain practical insights into creating and managing metadata effectively, equipping you to enhance the discoverability, accessibility, and reusability of research data in an evolving scientific landscape.
Metadata plays a pivotal role in research data management by ensuring that data is discoverable, accessible, and usable. Without proper metadata, even highly valuable datasets may remain difficult to locate, understand, or reuse.
Key reasons why metadata is vital in RDM:
- data discovery: metadata makes data findable by cataloguing essential details, enabling both humans and machines to search for and locate data;
- data contextualization: metadata provides context, such as who created the data, when, and under what conditions, making the data meaningful and easier to interpret for new users;
- interoperability: metadata standardizes descriptions and terminologies, enabling seamless integration of data from diverse sources and formats, which supports cross-disciplinary research;
- data reusability: well-documented metadata ensures that other researchers can correctly interpret and reuse data, extending it’s lifespan and maximizing its scientific impact;
- compliance with standards: many funding agencies mandate the inclusion of metadata as part of data management plans, ensuring alignment with FAIR principles;
- data security and privacy: metadata can include information about access restrictions and sensitivity levels, ensuring that data is used responsibly and in accordance with ethical guidelines.
- enhanced collaboration: well-structured metadata facilitates collaboration by allowing multiple researchers or teams to understand and work with the same data seamlessly;
- long-term preservation: metadata ensures that data remains interpretable and usable over time, even as technologies evolve, by documenting technical formats, software, and dependencies;
- performance measurement: metadata enables tracking and assessing the impact of data usage, such as citation metrics and contributions to publications.
By enriching research data with high-quality metadata, researchers can significantly enhance its discoverability, reputation, and impact within the scientific community.
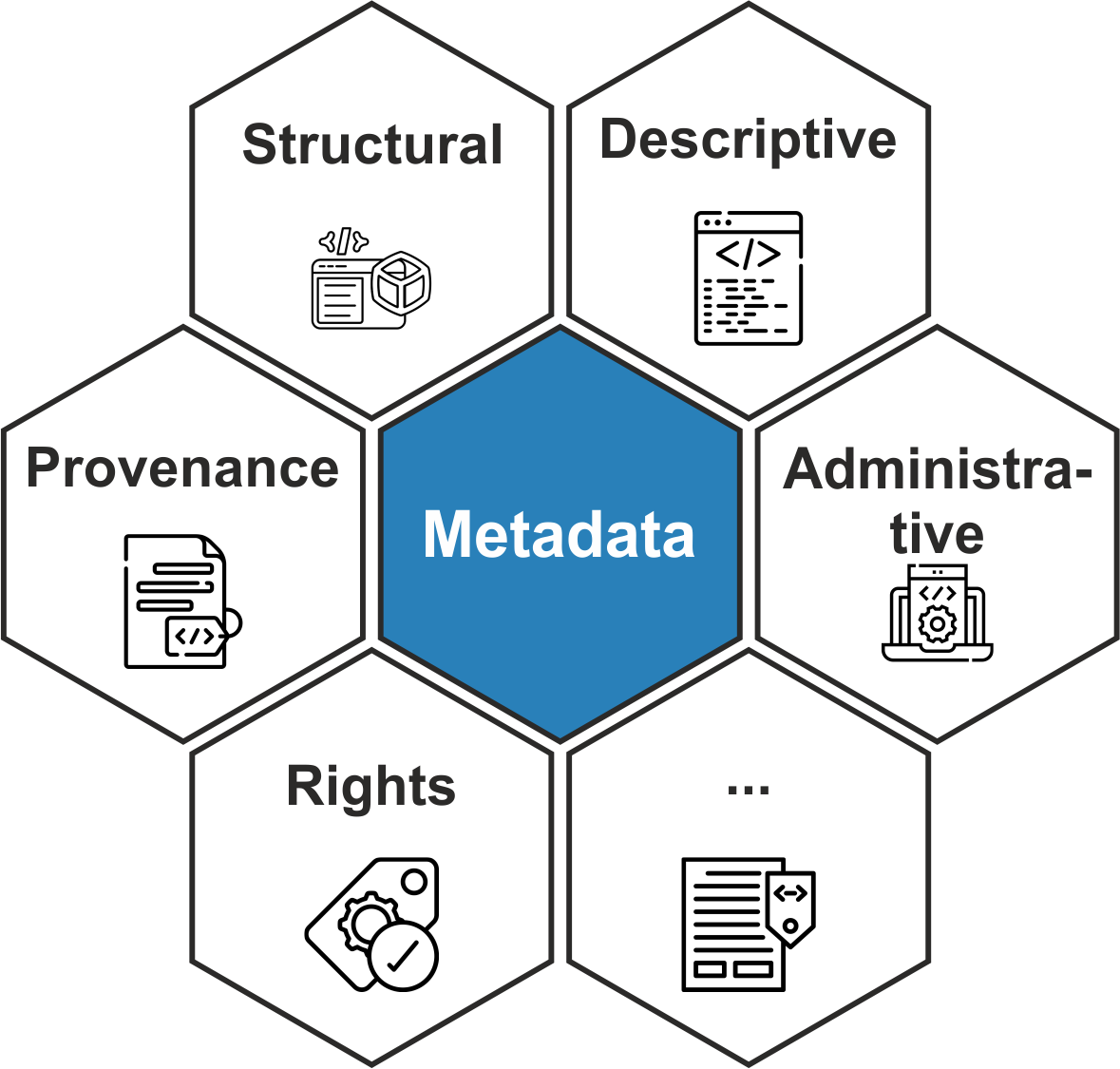
Metadata in research data management can be divided into distinct categories based on its purpose and the type of information it provides. These categories work together to ensure data is accessible, understandable, and well-documented throughout its lifecycle. By understanding the different types of metadata, researchers can effectively manage and share their datasets to maximize their impact.
Primary types of metadata in RDM:
- descriptive metadata provides key details that help users identify and locate datasets. It includes elements such as the title, author, abstract, and keywords. Descriptive metadata are often searchable, making it critical for data discovery in repositories and databases. For example, the use of keywords allows both human users and automated systems to efficiently find relevant datasets based on topics of interest;
- structural metadata describes the organization and relationships within a dataset. It includes information such as file formats, hierarchies, sequences of data elements, and connections between different parts of the data. This metadata is especially important for understanding complex datasets or systems that involve multiple interconnected files, such as relational databases or layered geographic information systems (GIS);
- administrative metadata supports the management and preservation of data. It typically includes details about ownership, access permissions, data usage restrictions, and version control. Additionally, this type often encompasses technical metadata, such as file sizes, creation and modification dates, software requirements, and storage locations. Administrative metadata ensures that datasets remain usable and secure over time.
Additional subtypes of metadata:
- provenance metadata tracks the history and origin of a dataset. It documents where the data came from, how it has been modified, and who has contributed to it. This type of metadata is particularly valuable for ensuring reproducibility and verifying the integrity of research data;
- rights metadata provides information on licensing and usage rights associated with the dataset. It defines who can access the data, how it can be used, and any legal or ethical considerations. This metadata helps prevent misuse and ensures compliance with intellectual property laws.
Expanded insights and additional metadata types. In addition to the core categories, metadata can take on specialized roles depending on the context of the research or data type:
- technical metadata, as a subset of administrative metadata, focuses specifically on the technical aspects of the data, such as encoding formats, compression techniques, or required software environments. This information is vital for data preservation and interoperability;
- disciplinary metadata – some fields of research have specific metadata standards tailored to their needs, such as the Darwin Core for biodiversity data or DDI (Data Documentation Initiative) for social science data. Using such domain-specific metadata ensures consistency and usability within particular disciplines;
- temporal metadata records details about the timeframes covered by the data, including timestamps, intervals, or chronological sequences. This is essential in fields like climate science, historical research, or event tracking.
Each type of metadata plays a unique and complementary role in research data management. Together, they form a cohesive framework that supports data discoverability, usability, preservation, and compliance with legal and ethical standards.
Creating effective metadata is essential for ensuring that research data remains accessible, understandable, and reusable over time. This process requires careful planning, adherence to standards, and a commitment to detail. By following established best practices, researchers can produce metadata that is clear, comprehensive, and beneficial for both immediate collaborators and future users.
Key best practices for metadata creation:
- use standardized metadata schemas: adopting widely recognized metadata schemas ensures consistency and compatibility across datasets and platforms. Examples include Dublin Core for general data, DataCite for dataset citations, and MIxS (Minimum Information about any (x) Sequence) for microbiome research. These schemas provide a framework for organizing metadata elements, making datasets more discoverable and interoperable (see metadata standards catalog by subjects or list of metadata standards);
- provide detailed descriptions: metadata should include clear and thorough descriptions of the dataset’s content, format, and context. This information should specify methodologies, tools, or instruments used in data collection, as well as any unique conditions or assumptions. Detailed metadata enhances understanding and usability for both current and future users;
- ensure metadata completeness: comprehensive metadata should address all essential aspects of the data, including its origin, structure, format, and permissions. Incomplete metadata can lead to misinterpretation or make datasets difficult to locate and reuse. A complete metadata record acts as a roadmap, guiding users through the dataset;
- use controlled vocabularies: employing controlled vocabularies and standardized terminologies ensures consistency in metadata entries. This practice supports better data discoverability across repositories and minimizes ambiguity in dataset descriptions. Controlled vocabularies are particularly important for domain-specific terms or technical jargon;
- regularly update metadata: metadata should evolve alongside the dataset. As changes occur – such as updates to the dataset, modifications to access rights, or the addition of new data elements – metadata should be revised to reflect these developments. Keeping metadata up-to-date ensures its accuracy and relevance;
- collaborate with metadata experts: consulting with metadata specialists, such as data librarians or domain-specific metadata professionals, can greatly enhance the quality and reliability of metadata. These experts can guide researchers in adhering to best practices and complying with relevant standards.
Additional best practices and insights:
- incorporate persistent identifiers: including persistent identifiers, such as DOIs (Digital Object Identifiers), in metadata ensures datasets can be consistently referenced and cited, increasing their visibility and traceability;
- document data provenance: metadata should capture the origin and history of the dataset, including details about data collection processes, modifications, and transformations. Provenance information ensures reproducibility and builds trust in the dataset;
- focus on user perspective: metadata should be written with future users in mind. Researchers should anticipate the questions and needs of potential users and ensure metadata addresses them comprehensively. Including a glossary of terms or explanatory notes can be helpful;
- leverage automated tools: using metadata generation tools or templates can streamline the creation process and ensure compliance with metadata standards. Automation reduces the likelihood of errors and enhances consistency;
- embed metadata in datasets: where possible, metadata should be embedded directly within data files or included as accompanying documentation. This approach ensures that metadata travels with the data, reducing the risk of separation or loss.
By adhering to these best practices, researchers can create high-quality metadata that maximizes the value, discoverability, and usability of their data. Well-crafted metadata ensures datasets can serve as enduring and reliable resources for future research.
Metadata management presents several challenges that researchers and institutions must address to ensure effective research data management. These challenges stem from the complexity of metadata creation, the need for adherence to standards, and the dynamic nature of research data:
- complexity and time requirements: creating detailed metadata can be a time-consuming and resource-intensive process, particularly for large datasets or complex research projects. Researchers may lack the expertise, time, or resources to create comprehensive metadata, potentially compromising the usability and discoverability of their data;
- lack of standardization across disciplines: different research fields often use varying metadata standards and requirements, making it challenging to adopt a universal approach. This lack of standardization complicates interdisciplinary research and can lead to inconsistencies in how metadata is created and interpreted;
- balancing detail and simplicity: finding the right balance between providing detailed metadata and keeping it simple enough to manage effectively is critical. Overly detailed metadata can be difficult to maintain, while insufficient metadata reduces the accessibility, discoverability, and usability of data. Researchers need to identify and apply appropriate levels of metadata detail for their projects;
- cost of metadata management: high-quality metadata creation requires resources, including time, labour, and often specialized software or services. Smaller institutions or research teams with limited funding may struggle to allocate the necessary resources for metadata management, resulting in inconsistent or incomplete metadata;
- technical barriers: metadata management tools and platforms may have steep learning curves or limited compatibility with certain data formats and types. Researchers may face challenges in adopting these tools, leading to inconsistent metadata application or the inability to meet standardized practices;
- long-term preservation: ensuring metadata remains readable, interpretable, and functional over the long term is a continuous challenge. As data formats, storage technologies, and standards evolve, metadata must be updated and maintained to preserve its utility for future research;
- integration with automated workflows: researchers often rely on automated tools for data collection and management, but integrating these workflows with metadata creation can be complex. Ensuring that metadata is generated and updated consistently within automated processes requires advanced planning and technical expertise;
- user-centric metadata design: creating metadata that meets the needs of diverse user groups – such as researchers, institutions, and the public – requires careful planning. Metadata that is too technical or too generalized may fail to address the needs of specific audiences, limiting its effectiveness;
- metadata duplication and redundancy: in collaborative or large-scale research projects, metadata can become duplicated or inconsistent due to a lack of communication and coordination among team members. Such issues can result in conflicting records and reduced data quality.
To overcome these challenges, institutions and researchers must invest in metadata training programs, develop standardized workflows, and collaborate with metadata experts. Additionally, adopting advanced tools, integrating metadata into automated processes, and planning for long-term maintenance can significantly improve the quality, consistency, and sustainability of metadata management practices.
Metadata is continually evolving in response to advancements in technology, shifts in research practices, and a growing emphasis on open science and the FAIR principles. Future metadata practices are expected to incorporate innovative tools, standards, and automation processes that will revolutionize metadata creation and management.
Emerging trends and future directions:
- automated metadata generation: artificial intelligence (AI) and machine learning (ML) are poised to automate significant aspects of metadata creation. These technologies can extract relevant metadata directly from research outputs, reducing the time and effort required by researchers while also improving metadata accuracy and consistency. Automation could enable metadata to be more comprehensive and adaptable to different datasets and contexts;
- semantic metadata and linked data: semantic technologies, such as RDF (Resource Description Framework), enable metadata to link datasets in meaningful ways. These technologies create interconnected data networks, facilitating data discoverability and interoperability. By incorporating linked data principles, metadata can provide richer context and connections across diverse research domains;
- real-time metadata updates: emerging systems are likely to support real-time updates of metadata. This capability ensures users have access to the most current information, allowing for better tracking of changes in data, including provenance and version control. Real-time updates could also streamline the process of integrating metadata into collaborative research environments;
- enhanced interoperability standards: ongoing efforts to establish universal and interoperable metadata standards across disciplines will continue to play a pivotal role in metadata development. These standards will enable seamless cross-disciplinary data sharing, enhancing the usability and scientific impact of research data;
- integration with blockchain technology: blockchain offers the potential to create secure, verifiable records of metadata changes. By providing a trusted history of data modifications, blockchain could improve transparency and reproducibility. This technology may also support decentralized metadata management, further securing metadata from unauthorized alterations;
- improved metadata management platforms: as tools for managing metadata advance, researchers will benefit from platforms that integrate metadata creation, storage, and sharing in a unified environment. These platforms will streamline workflows, simplify compliance with metadata standards, and reduce barriers to effective metadata management;
- dynamic metadata personalization: future systems may incorporate customizable metadata frameworks that adapt to specific research needs or domains. Personalized metadata templates and intelligent recommendations could enhance relevance and ease of use, catering to diverse research contexts;
- integration with virtual and augmented reality: with the rise of immersive technologies, metadata may expand to include annotations and attributes for 3D models or virtual environments. This trend will be especially impactful for fields like archaeology, engineering, and medical simulations.
The future of metadata in research data management promises significant improvements in efficiency, consistency, and reliability. These developments will ensure that research data is well-documented, easily discoverable, and reusable. As metadata practices evolve, they will continue to align with the goals of research data management and the principles of FAIR, ultimately driving innovation and collaboration across scientific disciplines.
Farnel S., Shiri A. (2014). Metadata for research data: Current practices and trends. Proceedings of the International Conference on Dublin Core and Metadata Applications, pp. 74–82. DOI: 10.23106/dcmi.952136534
Greenberg J., Wu M.F., Liu W., Liu F. (2023). Metadata as data intelligence. Data Intelligence, Vol. 5, pp. 1–5. DOI: 10.1162/dint_e_00212
Mosha N.F., Ngulube P. (2023). Metadata standard for continuous preservation, discovery, and reuse of research data in repositories by higher education institutions: A systematic Review. Information, Vol. 14, pp. 1–17. DOI: 10.3390/info14080427
Pinoli P., Ceri S., Martinenghi D., Nanni L. (2019). Metadata management for scientific databases. Information Systems, Vol. 81, pp. 1–20. DOI: 10.1016/j.is.2018.10.002
Riley J. (2014). Understanding metadata: what is metadata, and what is it for? National Information Standards Organization (NISO); 45 p.
University of Cambridge. (2024). Metadata: What is it and why is it important? [online] [accessed 11/24/2024]. Available: https://www.data.cam.ac.uk/data-management-guide/metadata
University of Delaware. (2024). What is Metadata? [online] [accessed 11/24/2024]. Available: https://guides.lib.udel.edu/researchdata/metadata
University of New England. (2024). Metadata for Research Data. [online] [accessed 11/24/2024]. Available: https://www.une.edu.au/research/research-services/research-performance/research-data-management/metadata-for-research-data