Data life cycle
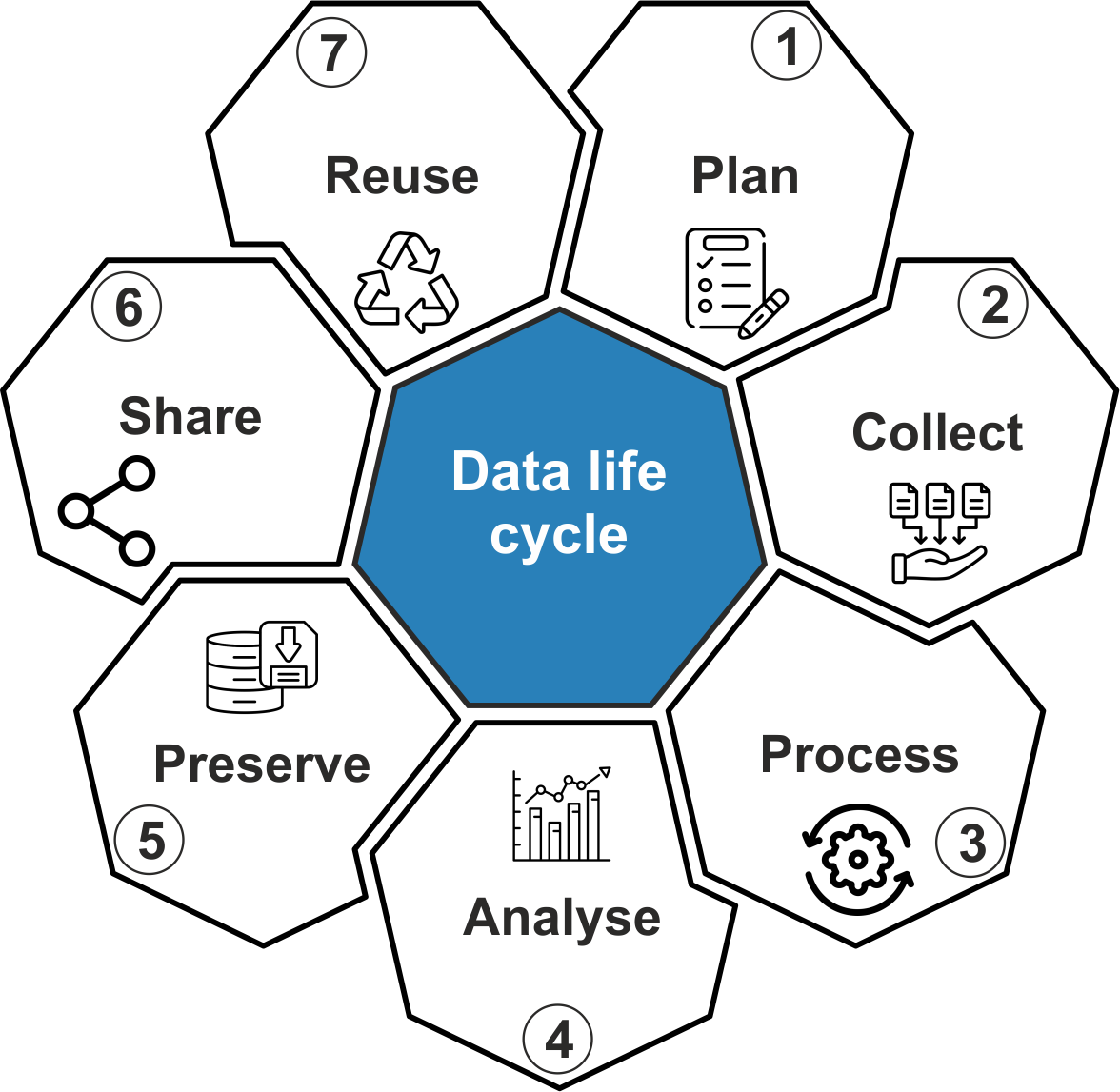 The data life cycle in research data management (RDM) refers to the stages that research data goes through, from its creation to its eventual archiving or disposal. When this cycle is properly managed, data is kept secure, reusable, accessible, and organized for the duration of its life.
The data life cycle in research data management (RDM) refers to the stages that research data goes through, from its creation to its eventual archiving or disposal. When this cycle is properly managed, data is kept secure, reusable, accessible, and organized for the duration of its life.
The data life cycle includes the following stages:
- planning: before data collection, researchers define the objectives, methods, storage, sharing, and ethical considerations, and establish compliance with funder and institutional requirements;
- collecting: data is gathered through experiments, observations, surveys, or simulations, all according to predefined methodologies;
- processing: raw data is cleaned, formatted, and organized for analysis;
- analysing: researchers examine the data using statistical, computational, or qualitative methods to generate insights and conclusions;
- storing & preservation: data is securely stored, following structured backup and access protocols, ensuring its integrity and preventing loss;
- sharing & publishing: data is made available in repositories or controlled-access systems, depending on data sensitivity, for others to access, reproduce, or validate research findings;
- reusing & archiving: data is either reused in new research or archived for long-term preservation.
The data life cycle significance in RDM:
- ensures data integrity: proper management prevents data loss, corruption, or unauthorized changes;
- enhances reproducibility: allows others to verify research findings and build on existing data;
- supports compliance: meets institutional, funder, and legal requirements for data handling, including ethical approvals, licensing, and data security measure;
- promotes efficiency: well-organized data saves time and effort in retrieval and reuse;
- facilitates collaboration: enables seamless data sharing among researchers via interoperable formats and repository standards.
The information in this section is arranged in accordance with the phases of the life cycle of research data. In this chapter, you’ll discover:
- each stage’s general description;
- a list of the primary factors that must be taken into account at every stage.
The planning stage in the data life cycle is the foundation of RDM. It involves preparing and strategizing how data will be collected, stored, processed, analysed, shared, and preserved throughout the research process. This stage ensures that data is handled efficiently, ethically, and in compliance with relevant policies and regulations and aligns with institutional and funder expectations.
Determining the approach intended for handling the data and documentation produced during the project is known as data management planning.
A data management plan (DMP) is a document that details various aspects of the data management process that take place prior to, during, and following the conclusion of a project (see also https://www.lbtu.lv/en/data-management-plans).
Well-structured DMP increases work efficiency and makes teamwork, as well as service and tool utilization, easier. Additionally, a thorough DMP would assist in improving the FAIRness of your research data.
Benefits of developing a DMP include the following:
- it helps plan and budget for necessary resources and equipment;
- it helps identify risks in data handling and apply solutions at an early stage;
- it makes data sharing, reuse, and preservation easier;
- it establishes roles, responsibilities, and compliance with funder and institutional requirements.
A number of factors should be considered when creating a plan for data management:
- when applying for grants or after the project has been funded, research organizations and funders frequently demand a DMP. As a result, take into account the rules, regulations, and resources your funder requires for data management planning;
- the DMP should ideally be completed prior to beginning data collection. However, it should be updated as the research project develops to reflect changes in the infrastructure, research software, or innovative collaboration, for example;
- take into account standards or best practices that are required by the facilities and infrastructures that you intend to use;
- find recommendations and get assistance from your institution’s support services, such as the IT department, library, data managers or data stewards, legal or tech transfer team, and data protection officer.
Key components of the planning stage:
- defining research objectives: identify the research questions and objectives. Determine the type of data needed (quantitative, qualitative, primary, secondary);
- data collection methods: decide how data will be collected (experiments, surveys, fieldwork, etc.), and choose formats, tools, and instruments for data collection;
- metadata and documentation: establish metadata standards for data description, and plan for documentation to ensure data context and reproducibility;
- ethical and legal considerations: address privacy, consent, and data protection issues, and ensure compliance with ethical guidelines and regulations (e.g., GDPR, HIPAA);
- data storage and security: identify storage locations (local servers, cloud storage, institutional repositories), and plan data backup strategies and access control measures;
- data sharing and accessibility: determine how and when data will be shared, and choose repositories for data publishing and ensure compliance with open data policies;
- data management plan (DMP): create a formal document outlining all aspects of data handling. Many funding agencies and institutions require a DMP as part of grant applications.
By carefully planning in advance, researchers can ensure data integrity, accessibility, and long-term usability, making their research more reliable and impactful.
The process of gathering information about particular variables of interest through the use of instruments or other techniques is known as data collection. The data collection stage is a crucial phase in RDM, as it involves gathering data necessary for research objectives. Proper collection ensures data accuracy, reliability, and usability for analysis and future use.
Additionally, you can use existing data in your project (refer to the “Reusing & Archiving” section for more information).
Implementing quality control measures and properly documenting data collection procedures are crucial. Data can be managed and documented during collection by using the right tools. Electronic Lab Notebooks (ELNs), Electronic Data Capture (EDC) systems, and Laboratory Information Management Systems (LIMS) are appropriate instruments for data management and documentation during data collection. Additionally, file-sharing and collaborative research platforms on the internet could be utilized as ELNs or data management systems.
Key aspects of the data collection stage:
- defining data needs: identify research questions and objectives; determine the type and format of data required (quantitative, qualitative, structured, unstructured). Structured data follows a predefined format, whereas unstructured data requires additional processing before analysis;
- choosing data collection methods:
- primary data collection (new data directly gathered by researchers): surveys, interviews, focus groups; Experiments and simulations; observations and fieldwork; sensor data or real-time monitoring;
- secondary data collection (existing data from other sources): government reports, databases, and repositories; published research, books, and articles; social media and web-scraped data; however, before using secondary data, researchers should assess its reliability, relevance, and potential need for reformatting;
- data collection tools and technologies, where manual methods offer flexibility, digital and automated tools enhance efficiency and minimize human error:
- manual tools: paper forms, notebooks, voice recordings;
- digital tools: online surveys, databases, electronic lab notebooks;
- automated methods: Web scraping, APIs, IoT sensors;
- ensuring data quality and integrity: minimize errors through standardized data collection protocols; use validation techniques such as duplicate entry checks, outlier detection, and consistency checks; whereas quality control should be applied both at the point of collection and in later processing stages to maintain accuracy;
- ethical considerations and compliance: obtain necessary approvals (e.g., institutional review boards, ethical committees); ensure informed consent for human participant data; follow data protection regulations (e.g., GDPR, HIPAA) for sensitive data; for datasets containing personally identifiable information (PII), anonymization or pseudonymization techniques should be applied where necessary;
- data documentation and metadata creation: record information about data collection methods, tools, dates, and contributors; create metadata using standardized formats to improve long-term usability and interoperability (see also https://www.lbtu.lv/en/metadata);
- secure storage and backup: store raw data securely in repositories or cloud-based systems; maintain backup copies to prevent data loss (see also https://www.lbtu.lv/en/data-deposit).
By carefully planning and executing the data collection stage, researchers ensure that their data is accurate, ethical, well-documented, and ready for analysis.
Data processing involves organizing, cleaning, transforming, and preparing data for analysis. This stage ensures that raw data is converted into a structured and usable format while maintaining accuracy and integrity.
Processing’s primary goals are to:
- transform data into a readable format, ensuring compatibility with analytical tools;
- eliminate faulty or low-quality data to produce a clean, high-quality dataset for trustworthy outcomes.
Processing can also involve manual steps to prepare data for analysis when it is imported from external or previously collected sources, such as data reused from another project. These actions consist of, but are not restricted to:
- altering data structure so that various datasets can be integrated with one another;
- bringing all of the data to the similar level by changing the coding systems or ontologies;
- filtering data so that only information appropriate for the project is kept.
Effective data processing is crucial for ensuring data quality and usability in analysis. Combining two or more datasets into a single dataset also requires accurate data processing. The reproducibility of your results depends on thorough documentation of each processing step. Properly executed data processing improves efficiency, enhances organization, and facilitates accurate analysis.
Key components of the data processing stage:
- data cleaning and validation: detect and correct errors, inconsistencies, or missing values; standardize formats and remove duplicate or irrelevant data; validate data for accuracy and completeness;
- data transformation: convert raw data into a structured format (e.g., from unstructured text to tables); normalize, aggregate, or categorize data to align with research needs; apply coding or classification schemes for qualitative data;
- data integration: merge datasets from different sources while ensuring consistency; align variables and standardize formats for compatibility;
- data anonymization and security measures: remove personally identifiable information (PII) if required; apply encryption or access controls to protect sensitive data;
- metadata generation: document processing steps for transparency and reproducibility;
- intermediate storage and backup: store processed data securely to prevent loss; implement backup strategies for data protection.
By properly managing the data processing stage, researchers ensure that their data is clean, reliable, and ready for analysis, ultimately improving research quality and reproducibility.
The data analysis stage in the life cycle is a crucial phase where processed data is examined, interpreted, and transformed into meaningful insights. This stage involves applying statistical, computational, or qualitative methods to extract patterns, relationships, and conclusions that support research objectives.
Data analysis can be regarded as a step at which new information and knowledge are produced. The analysis workflow applied to a dataset must adhere to the FAIR principles due to the importance of the data analysis stage in research findings. Furthermore, it is crucial that other scientists and researchers can replicate the analysis process. More data-intensive projects will emerge as more disciplines become data-oriented, necessitating the expertise of specialists in different fields.
You must first consider the computing environment and select from a variety of computing infrastructure types, such as cloud and local servers, before you can begin data analysis. Depending on your requirements and level of experience, you must also choose the right work environment (online web based tools or locally installed ones). The tools that are most appropriate for analysing your data must be carefully selected based on analytical needs.
It is crucial to document the precise procedures followed for data analysis. This covers the computing environment, parameters, and software version that was used. Manual data manipulation should be minimized or thoroughly documented to ensure reproducibility.
When it comes to collaborative data analysis, it is important to ensure that everyone involved has access to the data and tools. This can be accomplished by creating virtual research environments that support data sharing and real-time collaboration.
Consider publishing both the datasets and the analysis process in accordance with the FAIR principle (see also https://www.lbtu.lv/en/fair-principles-and-data).
Key components of the data analysis stage:
- selecting analytical methods: choose appropriate techniques (e.g., statistical analysis, machine learning, qualitative coding); ensure methods align with research questions and data types;
- applying statistical and computational tools: use software like R, Python, SPSS, NVivo, or MATLAB for analysis; perform descriptive and inferential statistics, text mining, or trend analysis;
- exploratory data analysis (EDA): identify patterns, correlations, and anomalies in the dataset; use data visualization techniques (graphs, charts, heatmaps) to summarize findings;
- hypothesis testing and modelling: test research hypotheses using appropriate statistical tests (e.g., t-tests, ANOVA, regression analysis); develop predictive or explanatory models where applicable;
- interpreting results: draw meaningful conclusions from the analysis; compare findings with existing literature or theoretical frameworks;
- ensuring reproducibility and transparency: document the analysis workflow, including code, formulas, and decision-making steps; use version control systems (e.g., GitHub, OSF) to track changes;
- ethical considerations: ensure unbiased interpretation of results; maintain confidentiality and integrity in data handling.
By effectively managing the data analysis stage, researchers can generate valid and reliable insights, contributing to high-quality and reproducible research outcomes.
The data storing & preservation stage ensures data remains accessible, secure, and usable over time. Proper storage and preservation allow for future validation, reuse, and compliance with institutional and funding agency requirements.
Research data should be preserved for a number of reasons:
- ensure that the data can be replicated and validated for a number of years after the project is finished;
- permit data reuse for other objectives, like education or additional research;
- meet the requirements of funders, publishers, institutions, and organizations for data retention over a specified period;
- preserve information of importance to a company, a country, the environment, or society as a whole.
Data preservation needs to be handled by professionals and committed services. Planning, regulations, resources (people, money, and time), and the appropriate technology are all necessary for the preservation of digital information in order to maintain its functionality and accessibility (refer to ISO Standards for quality, preservation, and integrity of information). Therefore, for digital preservation, specific long-term data repositories should be used, where information integrity is tracked and data is actively maintained.
Consider the following approaches:
- speak with your institution’s data centre, library, or IT department;
- verify whether national services are offered;
- depending on the type of data, select reliable deposition databases or research repositories. Some repositories allow open access publication, enhancing visibility and reuse.
A number of conditions must be met in order to prepare data for preservation:
- data that is mutable or temporary should not be included;
- make sure the documentation is clear and self-explanatory;
- provide details regarding origin;
- provide enough licensing details;
- make sure the data is organized properly;
- make sure that the naming convention is applied consistently;
- instead of using proprietary file formats, use open source, standard ones.
If non-digital data (like paper) must be preserved, think about whether digitizing the data is practical or speak with your institution’s data management support services.
Key components of the data storing & preservation stage:
- choosing storage solutions: select appropriate storage options (local servers, cloud storage, institutional repositories); use redundant storage systems to prevent data loss;
- data organization and file management: follow a structured file naming and folder organization system; use standardized formats (e.g., CSV, XML, PDF/A) for long-term accessibility;
- implementing data security measures: apply encryption, access controls, and authentication protocols; ensure compliance with data protection regulations (e.g., GDPR, HIPAA);
- creating data backups: use automated backup strategies (e.g., daily, weekly, offsite backups); store backups in multiple locations to reduce risk of loss;
- metadata and documentation: maintain comprehensive metadata to describe data content, structure, and context; ensure documentation includes details on file formats, variables, and methodologies;
- long-term preservation strategies: use digital repositories (e.g., Zenodo, Dryad, institutional archives); migrate data to newer formats as technology evolves to prevent obsolescence;
- ensuring data accessibility: define clear data sharing policies and access permissions; assign persistent identifiers (DOI, handles) for citation and retrieval.
By effectively managing the data storing and preservation stage, researchers ensure that valuable datasets remain secure, reusable, and sustainable for future research, verification, and replication.
The data sharing and publishing stage in the life cycle is essential as it ensures that research data is made available to other researchers, institutions, and the public for validation, reuse, and further study. Proper data sharing and publishing enhance research transparency, reproducibility, and impact.
You can publish your data to make it available to the world’s research community and society, or you can share it with your collaboration partners as part of a joint research project.
It’s critical to understand that data sharing does not equate to public or open data. You have the option of sharing your data with closed or restricted access. Furthermore, publishing a paper or manuscript in a journal is not the same as sharing or publishing data. Here, we concentrated on data rather than papers or articles, such as raw observations and measurements, analysis workflows, code, etc.
While data sharing can occur at any stage of the research data life cycle, it should ideally occur when articles that use the data to draw scientific conclusions are published.
Nowadays, many research funders, organizations, and major journals and publishers have data sharing policies that are mandatory unless restricted for ethical, legal, or contractual reasons. The European Code of Conduct for Research Integrity advises making data “as open as possible, as closed as necessary,” even though it may not be feasible to share all data publicly for ethical, legal, contractual, or intellectual property reasons. Making the data as FAIR as possible will guarantee that it can be used to its fullest potential in the future.
It should be possible to choose the appropriate kind of access for the data based on the previously mentioned factors. Openly and publicly sharing your data’s metadata is a good idea, even if access to the data is restricted:
- open access: information is made publicly available. The data is freely accessible to everyone;
- registered access: users must register and agree to repository usage guidelines before accessing the data. User consents to follow the data usage guidelines of repositories that serve the shared data, and the institution guarantees the “researcher” status. Except for the requirement that the data be used for research, datasets shared through registered access usually have no restrictions. Repositories track user access and enforce terms of use;
- Data Access Committees (DACs) or controlled access: only researchers whose work has been examined and approved by a DAC are permitted access to data. A DAC is a group of one or more designated individuals in charge of releasing data to outside requestors in accordance with predetermined standards (research topics, permitted geographic areas, permitted recipients, etc.). The organization’s website typically outlines the criteria set by DAC for data access;
- access upon request (discouraged): requires a data owner or administrator to manually review and approve requests. The contact information of the data owner must be included in the metadata and it should remain publicly available even if data access is restricted.
Key components of the data sharing and publishing stage:
- selecting a data repository: choose an appropriate repository (e.g., Zenodo, Dryad, Figshare, institutional repositories); ensure compliance with funder and institutional policies;
- applying open data principles: follow FAIR principles (Findable, Accessible, Interoperable, Reusable); use open-access platforms when possible to maximize data reach;
- data licensing and access control: define permissions using licenses like Creative Commons (CC BY, CC0) or institutional policies; set access levels (open, restricted, embargoed) based on ethical or legal considerations;
- publishing metadata and documentation: provide clear metadata to describe the dataset (e.g., file formats, collection methods, variables); include README files, codebooks, and contextual information for usability;
- assigning persistent identifiers (PIDs): use DOIs (Digital Object Identifiers) or other PIDs for dataset citation and tracking; link datasets to research publications for better visibility and integration;
- complying with ethical and legal guidelines: ensure privacy protection and compliance with GDPR, HIPAA, or other guidelines; de-identify or anonymize sensitive data when required;
- encouraging reuse and citations: promote data availability in research articles and conference presentations; encourage proper citation of datasets in academic publications.
By effectively managing the data sharing & publishing stage, researchers enhance the visibility, credibility, and long-term impact of their work while contributing to the global research community.
The data reusing and archiving stage ensures that data remains accessible for future use, verification, and new research applications. Proper archiving preserves data integrity, while reuse promotes efficiency, innovation, and collaboration in research. Reusing data entails using it for objectives different from those for which it was initially gathered. In science, data reuse is especially crucial because it enables multiple researchers to independently analyse and publish findings based on the same data. One essential element of the FAIR principles is reusability.
Reusing existing data allows you to:
- obtain reference data for your research;
- avoid conducting unnecessary new experiments;
- conduct analyses to confirm reported findings, strengthening subsequent findings;
- increase the robustness of research by combining results from various samples or methods;
- obtain new insights by connecting and meta-analysing datasets.
Reusing current data requires making sure the requirements are fulfilled:
- investigate various sources for data that can be reused. Searching for value-added databases with carefully chosen content can be a good place to start. Additional options include getting data straight from the author of a scientific paper or looking through data deposition repositories for relevant datasets based on their annotation;
- verify the terms and conditions for data sharing and reuse. Ensure that a license is in place and it permits your intended actions;
- verify that sufficient metadata is available to enable data reuse. While some data types, like genome data, can be reused easily, others, like gene expression experiment data, may need a lot of metadata to be interpreted and used again;
- examine the data’s quality, meaning determine whether it is curated, from a reliable source, and whether it complies with standards;
- confirm that the information was gathered in an ethical manner and that the way you are using it complies with the rules and guidelines you must abide by. Before data can be accessed, there are typically technical and legal requirements for personal (sensitive) data. Therefore, there will be extra steps involved in gaining access to personal (sensitive) data;
- if you are reusing data that has been updated, be sure to note which version you are using. Think about how the modifications might affect your outcomes as well;
- if there is a persistent identifier (like a DOI), include it in the citation to properly credit the data.
Key components of the data reusing and archiving stage:
- ensuring data accessibility for reuse: store data in trusted repositories (e.g., Zenodo, Dryad, institutional archives); assign persistent identifiers (DOI, handles) to ensure easy citation and retrieval;
- promoting data reusability: adhere to FAIR principles (Findable, Accessible, Interoperable, Reusable); provide detailed metadata and documentation to help future users understand the dataset;
- enabling data discovery: publish data records in open-access databases and scholarly networks; use standardized metadata schemas (e.g., Dublin Core, DataCite) to improve dataset discoverability and indexing;
- applying data licensing for reuse: use Creative Commons (CC BY, CC0) or other licenses to clarify reuse permissions; clearly specify any access restrictions, such as ethical concerns or embargo periods;
- archiving data for long-term preservation: store data in format-neutral and non-proprietary file types (e.g., CSV, XML, PDF/A); ensure periodic data migration to prevent technological obsolescence;
- maintaining data integrity and versioning: implement version control to track changes over time; use checksum verification as a safeguard against data corruption or tampering;
- facilitating secondary research and collaboration: encourage researchers to reuse existing datasets to avoid redundant research and maximize resource efficiency; enhance interdisciplinary collaboration by ensuring cross-domain data accessibility.
By effectively managing the data reusing and archiving stage, researchers maximize the long-term value of their data, fostering new discoveries while ensuring sustainability and compliance with research policies.
Bossaller J., Million A. J. (2023). The research data life cycle, legacy data, and dilemmas in research data management. Journal of the Association for Information Science and Technology, Vol. 74, pp. 701–706. DOI: 10.1002/asi.24645
Elixir (2024). Data life cycle. [online] [cited 17/02/2025]. Available: https://rdmkit.elixir-europe.org/data_life_cycle (CC-BY)
Kvale L. H., Darch P. (2022). Privacy protection throughout the research data life cycle. Information Research, Vol. 27 (3), pp. 1–26. DOI: 10.47989/IRPAPER938
Shuliang L. (2024). Information Management. Springer; 506 p. DOI: 10.1007/978-3-031-64359-0
Zhang J., Symons J., Agapow P., Teo J. T., Paxton C. A., Abdi J., Mattie H., Davie C., Torres A. Z., Folarin A., Sood H., Celi L. A., Halamka J., Eapen S., Budhdeo S. (2022). Best practices in the real-world data life cycle. PLOS Digital Health, Vol. 1, pp. 1–14. DOI: 10.1371/journal.pdig.0000003