MI pētniecībā
 Mākslīgais intelekts (MI) ir kļuvis par būtisku rīku akadēmiskajā vidē, paātrinot pētniecības procesu. No literatūras apskata līdz datu analīzei un rezultātu sagatavošanai – MI automatizē uzdevumus, piedāvā jaunas analīzes iespējas un uzlabo datu izmantošanu.
Mākslīgais intelekts (MI) ir kļuvis par būtisku rīku akadēmiskajā vidē, paātrinot pētniecības procesu. No literatūras apskata līdz datu analīzei un rezultātu sagatavošanai – MI automatizē uzdevumus, piedāvā jaunas analīzes iespējas un uzlabo datu izmantošanu.
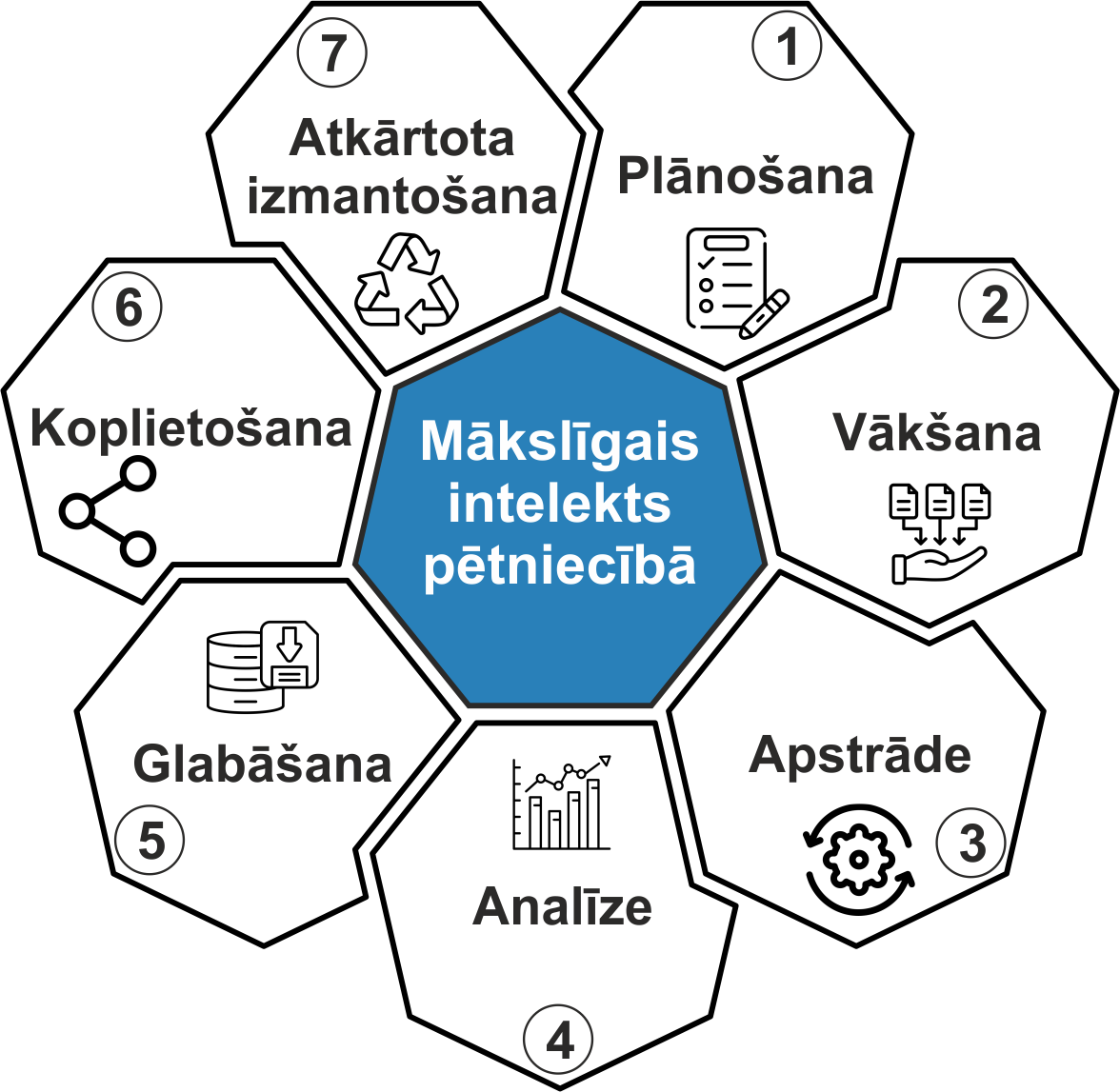
Pētniecības process ir ciklisks un sastāv no vairākiem posmiem: plānošanas, datu vākšanas, apstrādes, analīzes, saglabāšanas, dalīšanās un atkārtotas izmantošanas. Mākslīgais intelekts šajā procesā var palīdzēt, piemēram:
- veikt ātru literatūras analīzi;
- optimizēt datu apstrādi un anonimizāciju;
- uzlabot reproducējamību un metadatu sagatavošanu;
- atbalstīt zinātnisko rakstu veidošanu;
- uzlabot pētniecības integritāti, atklājot krāpšanu un pārbaudot plaģiātu.
Lai gan MI sniedz daudz priekšrocību, tā izmantošanai jāatbilst atbildīgai pētniecības praksei. Tas nozīmē:
- drošu un pārskatāmu datu pārvaldību;
- zinātniskā godīguma saglabāšanu;
- reproducējamības un atvērtības veicināšanu;
- AI izmantošanas fakta izpaušanu.
Šajā nodaļā jūs uzzināsiet par:
- mākslīgā intelekta pielietojumu pētniecībā – kādi ir galvenie uzdevumi pētniecības procesā, kurus var paveikt ar MI rīku palīdzību;
- ar MI izmantošanu saistītos ētiskos un juridiskos aspektus – datu drošības un privātuma aizsardzību, zinātniskās godīguma saglabāšanu, kā arī atvērtības un reproducējamības nodrošināšanu.
Mākslīgais intelekts (MI) arvien biežāk tiek integrēts pētniecības procesā, atvieglojot un paātrinot dažādus uzdevumus. Tā pielietojums aptver visu pētniecības ciklu – no pētījuma plānošanas līdz datu atkārtotai izmantošanai. Zemāk aprakstīti MI rīki un to iespējas dažādos pētniecības posmos.
1. Pētījuma plānošana ar MI
MI palīdz sistematizēt literatūras izpēti, veidot eksperimentu dizainu un sagatavot pētījumu pieteikumus:
- literatūras analīze – Elicit, Scite, Research Rabbit ātri atrod un apkopo saistītos zinātniskos avotus;
- eksperimentu plānošana – JASP, IBM SPSS Modeler palīdz veidot hipotēzes un eksperimentālos modeļus;
- pētījumu pieteikumu rakstīšana – ChatGPT, Claude, SciSpace asistē tekstu strukturēšanā un ideju formulēšanā;
- hipotēžu ģenerēšana – HyperWriter AI var palīdzēt noteikt nepilnības pētījumos un ierosināt jaunas hipotēzes.
2. Datu vākšana un apstrāde
MI automatizē datu apkopošanu, anotēšanu un aizsargā sensitīvu informāciju:
- automatizēta datu vākšana – BeautifulSoup + GPT apstrādā tīmekļa datus;
- tekstu un attēlu anotēšana – Prodigy, Doccano palīdz marķēt un kategorizēt datus;
- datu anonimizācija – Presidio, OpenDP nodrošina personas datu aizsardzību; uz mašīnmācībām balstītas anonimizācijas metodes piedāvā uzlabotu privātumu, vienlaikus saglabājot datu lietderību.
3. Datu analīze un interpretācija
MI veicina datu analīzi, statistisko apstrādi un kvalitatīvo datu kodēšanu:
- lielo datu apstrāde – Google AutoML, IBM Watson Studio, PyCaret veido un trenē analītiskos modeļus;
- statistiskā analīze – JASP, SmartPLS, DataRobot identificē datu sakarības;
- tematiskā kodēšana – NVivo, ATLAS.ti AI Coding atvieglo kvalitatīvo datu analīzi;
- novirzes noteikšana un mazināšana – holistiskais AI rīks piedāvā metodes, lai izmērītu un mazinātu novirzes dažādos uzdevumos, lai uzlabotu AI sistēmu uzticamību.
4. Datu saglabāšana un pārvaldība
MI palīdz organizēt un strukturēt pētniecības datus atbilstoši FAIR principiem:
- metadatu ģenerēšana – Dataverse AI plugins, DDI Metadata Standards strukturē pētniecības datus;
- datu organizēšana – FAIR Assistant, Datalore uzlabo datu pārvaldību;
- failu klasifikācija un meklēšana – Haystack, OpenAI embeddings atvieglo dokumentu pārvaldību.
5. Pētījumu rezultātu sagatavošana un izplatīšana
MI asistē zinātnisko rakstu sagatavošanā, vizualizācijā un izplatīšanā:
- rakstu rediģēšana – Trinka, Grammarly, ChatGPT uzlabo valodas kvalitāti;
- datu vizualizācija – Tableau AI, Datawrapper, Flourish automatizē grafiku veidošanu;
- pētījumu popularizēšana – SciSpace, Microsoft Copilot, TLDRThis veido saīsinātus kopsavilkumus un preses relīzes;
- AI atbalstīta atsauču ģenerēšana un pārbaude – dažādi rīki, piemēram, CitationGenerator, SciSpace Citation Generator nodrošina, ka citēšana ir precīza un novērš izdomātas atsauces.
6. Datu un pētījumu atkārtota izmantošana
MI atbalsta atvērto datu analīzi, reproducējamību un datu kopīgošanu:
- atvērto datu integrācija – Google Dataset Search kopā ar MI modeļiem palīdz atrast un analizēt papildu datus;
- reproducējamības pārbaude – Code Ocean, Whole Tale nodrošina reproducējamību;
- datu kopīgošana – Zenodo MI tagošana, Figshare MI rīki palīdz aprakstīt un publicēt pētniecības datus.
MI sniedz plašas iespējas pētniecībā, bet tā izmantošana prasa atbildīgu pētniecības praksi, nodrošinot datu drošību, reproducējamību un zinātnisko integritāti.
Mākslīgā intelekta (MI) izmantošana pētniecībā sniedz daudzas priekšrocības, tomēr tā lietošana prasa atbildīgu pieeju. Lai nodrošinātu, ka MI rīki tiek izmantoti saskaņā ar akadēmiskās ētikas un juridiskajām prasībām, būtiski ievērot atbildīgas pētniecības prakses principus. Tie ietver datu pārvaldības un privātuma aizsardzību, zinātniskās godīguma saglabāšanu, kā arī atvērtības un reproducējamības nodrošināšanu.
Visas līdzšinējās ētiskās un juridiskās prasības paliek spēkā arī MI izmantošanas gadījumā. Pētniekiem ir jāņem vērā šie principi, izvērtējot katra konkrētā MI rīka lietojumu, lai nodrošinātu, ka tas atbilst datu aizsardzības, intelektuālā īpašuma un zinātniskās integritātes standartiem.
1. Datu pārvaldība un privātuma aizsardzība
MI izmantošana pētniecībā nereti saistās ar lielu datu apjomu apstrādi, tostarp sensitīvu vai personu identificējošu informāciju. Lai nodrošinātu atbilstību privātuma aizsardzības prasībām, jāievēro:
- datu anonimizācija – piemēram, Presidio, OpenDP palīdz nodrošināt, ka personas dati tiek noņemti vai šifrēti;
- MI privātuma saglabāšanas modeļi – uz dziļu mācīšanos balstītas anonimizācijas metodes, piemēram, PriCheXy-Net, palīdz saglabāt privātumu, vienlaikus saglabājot datu integritāti;
- piekļuves kontrole – jāizmanto drošas datu glabāšanas un piekļuves sistēmas, lai novērstu neatļautu informācijas izmantošanu;
- regulatīvo prasību ievērošana – MI lietošana jāpielāgo normatīvajiem aktiem, piemēram, VDAR (GDPR) un citām datu aizsardzības regulām.
Būtisks risks! Personas datus drīkst ievietot un izmantot tikai tādās MI sistēmās, kas ir nepārprotami sertificētas VDAR prasību nodrošināšanai. Publiski pieejamie MI rīki (piemēram, ChatGPT, Claude) nav droši personas datu apstrādei, jo trūkst kontroles pār to, kur un kā šie dati tiek saglabāti.
2. Zinātniskā godīguma nodrošināšana
MI spēj ātri apkopot, ģenerēt un analizēt informāciju, taču tā pielietojumam jābūt kritiski izvērtētam, lai izvairītos no kļūdainiem vai sagrozītiem rezultātiem:
- datu avotu pārbaude – pirms izmantošanas MI ģenerētajai informācijai jāpārbauda avotu uzticamība un atbilstība zinātniskajiem standartiem;
- plaģiātisma un viltojumu novēršana – jāizmanto rīki, piemēram, Caps, Turnitin, iThenticate, lai pārliecinātos, ka MI ģenerētais teksts nav pārkopēts no esošiem avotiem;
- MI lēmumu caurspīdīgums – nepieciešams skaidrot, kā tiek iegūti un interpretēti MI analīzes rezultāti, lai izvairītos no neatbilstošu secinājumu izdarīšanas.
Būtisks risks! Nepublicētu rakstu un ideju ievietošana publiski pieejamās MI sistēmās var radīt šo ideju priekšlaicīgu publisku izpaušanu. Ja pētījuma rezultāti tiek apstrādāti komerciālos MI rīkos, tie var kļūt par daļu no treniņdatiem vai noplūst ārpus autora kontroles. Izmantojiet tikai iekšēji kontrolētas un drošas MI sistēmas!
3. Atvērtība un reproducējamība
Pētniecības reproducējamība un caurskatāmība ir būtiski akadēmiskās kopienas principi, kas jāievēro arī, izmantojot MI. Tomēr pastāv riski, kas var apdraudēt šo principu īstenošanu:
- datu un kodu publiska pieejamība – jānodrošina, ka izmantotie dati un algoritmi tiek dokumentēti un, ja iespējams, padarīti publiski pieejami, piemēram, izmantojot Zenodo, Figshare. Pastāv risks, ka MI ģenerētās analīzes netiek pietiekami skaidri dokumentētas, apgrūtinot to atkārtotu izmantošanu un pārbaudi;
- metadatu un metodoloģijas dokumentēšana – jāizmanto MI rīki, piemēram, Dataverse MI spraudņi, kas palīdz automātiski ģenerēt un strukturēt metadatus. Tomēr nepietiekama MI darbības pārskatāmība var radīt situācijas, kurās analīzes procesi nav skaidri reproducējami;
- rezultātu pārbaudāmība – lai nodrošinātu MI analīzes reproducējamību, jāizmanto versiju kontrole un kodu pārvaldības platformas, piemēram, Code Ocean. Pastāv risks, ka MI modeļi ģenerē rezultātus, kurus nevar viegli atkārtot vai pārbaudīt, ja nav pieejama detalizēta informācija par to darbības principiem un trenēšanas datiem.
Šo risku mazināšanai nepieciešams nodrošināt skaidru dokumentāciju un izmantoto MI rīku pārskatāmību, kā arī ievērot zinātniskās reproducējamības standartus.
4. Soļi MI izmantošanas risku mazināšanai
Lai nodrošinātu MI ētisku un juridiski atbilstošu lietošanu pētniecībā, jāievēro šādi principi:
- izvērtējiet MI rīkus – pārliecinieties, ka izmantotie MI rīki atbilst datu aizsardzības prasībām un nav pakļauti riskam izpaust sensitīvu informāciju;
- izmantojiet slēgtas sistēmas – ja nepieciešams apstrādāt konfidenciālus datus, izvēlieties institūcijas pārvaldītas MI platformas vai lokālus risinājumus;
- neievadiet sensitīvu informāciju publiskajos MI rīkos – personas dati, nepublicēti pētījumi un konfidenciāli materiāli nedrīkst tikt ievadīti publiski pieejamos MI rīkos;
- sekojiet MI attīstībai un regulējumam – MI tehnoloģijas un regulējumi attīstās strauji, tādēļ ir svarīgi sekot līdzi jaunākajām rekomendācijām un tiesiskajiem regulējumiem.
MI sniedz nozīmīgas iespējas pētniecībā, taču tā izmantošana jāveic ētiski un juridiski atbildīgi. Pētniekiem jābūt uzmanīgiem attiecībā uz datu privātumu, informācijas ticamību un zinātniskās atbildības ievērošanu, lai MI pielietojums atbilstu labākajām akadēmiskās prakses normām.
ALLEA | All European Academies. (2023). The European Code of Conduct for Research Integrity – Revised Edition 2023. ALLEA. DOI: 10.26356/ECOC
Asimopoulos D., Siniosoglou I., Argyriou V., Goudos S. K., Psannis K. E., Karditsioti N., Saoulidis T., Sarigiannidis P. (2024). Evaluating the Efficacy of AI Techniques in Textual Anonymization: A Comparative Study. IEEE, 2405.06709v1. Pieejams: https://arxiv.org/abs/2405.06709
European Comission. (2024) Living guidelines on the responsible use of generative AI in research. ERA Forum Stakeholders’ document. European Commission. Pieejams: https://research-and-innovation.ec.europa.eu/document/download/2b6cf7e5-36ac-41cb-aab5-0d32050143dc_en?filename=ec_rtd_ai-guidelines.pdf
Floridi L., Cowls J. (2019). A Unified Framework of Five Principles for AI in Society. Harvard Data Science Review, Issue 1.1., 14 p. DOI: 10.1162/99608f92.8cd550d1
Kocak Z. (2024). Publication Ethics in the Era of Artificial Intelligence. Journal of Korean Medical Science (JKMS), 39(33), e249. DOI: 10.3346/jkms.2024.39.e249
Sáinz-Pardo Díaz J., López García Á. (2024). An Open Source Python Library for Anonymizing Sensitive Data. Scientific Data, 11:1289. DOI: 10.1038/s41597-024-04019-z
Yousaf M. N. (2025). Practical Considerations and Ethical Implications of Using Artificial Intelligence in Writing Scientific Manuscripts. ACG Case Reports Journal, 12, e01629. DOI: 10.14309/crj.0000000000001629