Datu dzīves cikls
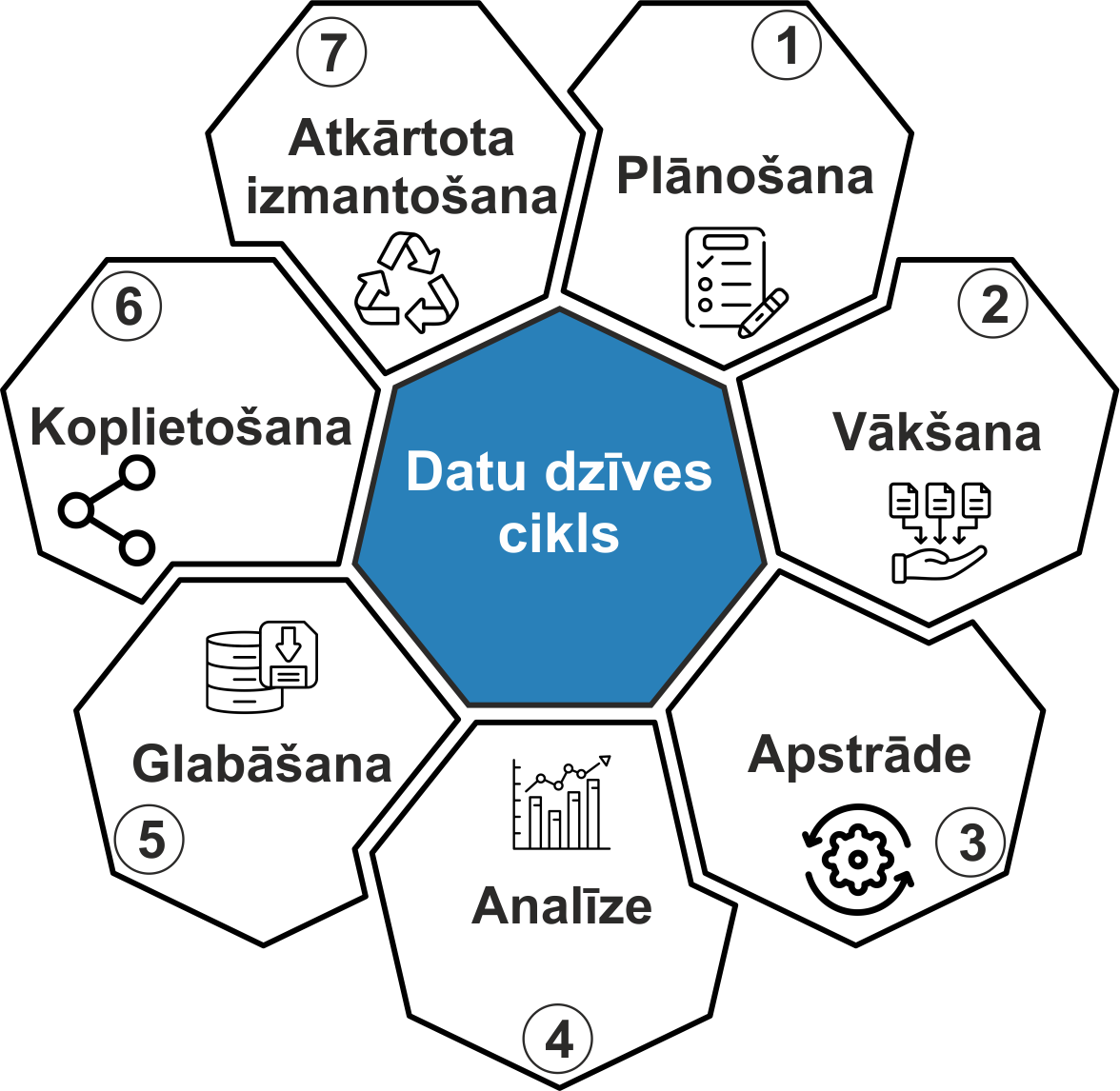 Datu dzīves cikls pētniecības datu pārvaldībā ietver posmus, kurus iziet pētniecības dati, sākot no to izveides līdz to iespējamai arhivēšanai vai iznīcināšanai. Ja šis cikls tiek pareizi pārvaldīts, dati tiek glabāti drošībā, ir pieejami, atkārtoti izmantojami un organizēti visā to dzīves cikla laikā.
Datu dzīves cikls pētniecības datu pārvaldībā ietver posmus, kurus iziet pētniecības dati, sākot no to izveides līdz to iespējamai arhivēšanai vai iznīcināšanai. Ja šis cikls tiek pareizi pārvaldīts, dati tiek glabāti drošībā, ir pieejami, atkārtoti izmantojami un organizēti visā to dzīves cikla laikā.
Datu dzīves cikls ietver šādus posmus:
- plānošana: pirms datu vākšanas pētnieki nosaka mērķus, metodes, uzglabāšanas, koplietošanas un ētiskos apsvērumus, kā arī atbilstību finansētāja un institucionālajām prasībām;
- vākšana: dati tiek vākti, izmantojot eksperimentus, novērojumus, aptaujas, simulācijas u.tml., saskaņā ar iepriekš noteikto metodiku;
- apstrāde: neapstrādātie dati tiek tīrīti, formatēti un sakārtoti analīzei;
- analīze: pētnieki pēta datus, izmantojot statistikas, skaitļošanas vai kvalitatīvās metodes, lai radītu atziņas un secinājumus;
- glabāšana un saglabāšana: dati tiek droši uzglabāti, atbilstoši strukturētiem dublēšanas un piekļuves protokoliem, nodrošinot to integritāti un novēršot zudumus;
- koplietošana un publicēšana: dati tiek padarīti pieejami citiem krātuvēs vai kontrolētas piekļuves sistēmās, atkarībā no datu jutīguma, lai varētu tos izmantot, atkārtot vai apstiprināt pētījuma rezultātus;
- atkārtota izmantošana un arhivēšana: dati tiek atkārtoti izmantoti jaunos pētījumos vai arhivēti ilgtermiņa saglabāšanai.
Datu dzīves cikla nozīme pētniecības datu pārvaldībā:
- nodrošina datu integritāti: pareiza pārvaldība novērš datu zudumus, bojājumus vai nesankcionētas izmaiņas;
- uzlabo reproducējamību: ļauj citiem pārbaudīt pētījumu rezultātus un balstīties uz esošajiem datiem;
- atbalsta prasību ievērošana: nodrošina atbilstību institucionālajām, finansētāju un juridiskajām prasībām attiecībā uz datu apstrādi, ieskaitot ētiskus apstiprinājumus, licencēšanu un datu drošības pasākumus;
- veicina efektivitāti: labi organizēti dati ietaupa laiku un līdzekļus to iegūšanā un atkārtotā izmantošanā;
- atvieglo sadarbību: nodrošina ērtu datu apmaiņu starp pētniekiem, izmantojot sadarbspējīgus formātus un repozitoriju standartus.
Šīs sadaļas informācija ir sakārtota atbilstoši pētniecības datu dzīves cikla posmiem. Šajā sadaļā dots:
- katra posma vispārīgs apraksts;
- galveno faktoru uzskaitījums, kas jāņem vērā katrā no posmiem.
Plānošanas posms datu dzīves ciklā ir pētniecības datu pārvaldības pamats. Tas ietver sagatavošanos un stratēģijas izstrādi attiecībā uz to, kā dati tiks vākti, glabāti, apstrādāti, analizēti, kopīgoti un saglabāti visā pētniecības procesa gaitā. Šis posms nodrošina, ka dati tiek pārvaldīti efektīvi, ētiski un saskaņā ar attiecīgajām politikām un normatīvajiem aktiem.
Datu pārvaldības plānošana ir process, kurā tiek noteikts, kā projekta laikā tiks apstrādāti un glabāti dati un dokumentācija.
Datu pārvaldības plāns (DPP) ir dokuments, kas detalizēti apraksta dažādus datu pārvaldības aspektus pirms projekta uzsākšanas, tā laikā un pēc tā noslēguma (skatīt arī https://www.lbtu.lv/lv/datu-parvaldibas-plani).
Datu pārvaldības plāna veidošana un pētījumu datu aizsardzība ir laba pētniecības prakse. DPP uzlabo darba efektivitāti un atvieglo komandas darbu, kā arī pakalpojumu un rīku izmantošanu. Turklāt visaptverošs DPP palīdz uzlabot pētniecības datu atbilstību FAIR principiem.
DPP izstrādāšanas ieguvumi:
- palīdz ieplānot nepieciešamos resursus un aprīkojumu;
- palīdz identificēt riskus datu apstrādē un savlaicīgi piemērot risinājumus;
- atvieglo datu koplietošanu, atkārtotu izmantošanu un saglabāšanu;
- nosaka lomas, pienākumus un atbilstību finansētāja un institucionālajām prasībām.
Veidojot datu pārvaldības plānu, jāņem vērā šādi faktori:
- piesakoties grantam vai saņemot finansējumu, pētniecības organizācijas un finansētāji bieži pieprasa DPP. Tāpēc ir svarīgi ņemt vērā noteikumus, prasības un resursus, ko finansētājs paredz datu pārvaldības plānošanai;
- ideālā gadījumā DPP jāizstrādā pirms datu vākšanas uzsākšanas. Tomēr DPP ir dzīvs darba dokuments, ko jāatjauno pētniecības projekta gaitā, ņemot vērā izmaiņas infrastruktūrā, pētniecības programmā vai sadarbībā;
- jāņem vērā standarti un labās prakses, ko pieprasa iekārtas un pakalpojumi, kurus paredzēts izmantot;
- tā kā DPP aptver daudzus dažādus aspektus, ieteicams meklēt palīdzību no institūcijas atbalsta dienestiem, piemēram, IT nodaļas, bibliotēkas, datu kuratoriem, juridiskās vai tehnoloģiju pārneses nodaļas un datu aizsardzības speciālista.
Plānošanas posma galvenie elementi:
- pētniecības mērķu definēšana: identificēt pētniecības jautājumus un mērķus, noteikt nepieciešamo datu veidu (kvantitatīvi, kvalitatīvi, primāri, sekundāri);
- datu vākšanas metodes: noteikt, kā dati tiks iegūti (eksperimenti, aptaujas utt.), kā arī izvēlēties formātus, rīkus un instrumentus datu vākšanai;
- metadati un dokumentācija: izvēlēties metadatu standartus datu aprakstam un plānot dokumentāciju, lai nodrošinātu datu kontekstu un reproducējamību;
- ētiskie un juridiskie apsvērumi: risināt privātuma, piekrišanas un datu aizsardzības jautājumus un nodrošināt atbilstību ētikas vadlīnijām un normatīvajiem aktiem, piemēram, Vispārīgajai datu aizsardzības regulai VDAR;
- datu glabāšana un drošība: identificēt glabāšanas vietas (lokālie serveri, mākoņkrātuves, institucionālie repozitoriji) un plānot datu rezerves dublēšanas stratēģijas un piekļuves kontroles pasākumus;
- datu koplietošana un pieejamība: noteikt, kā un kad dati tiks kopīgoti. Izvēlēties repozitorijus datu publicēšanai un nodrošināt atbilstību atvērto datu politikām;
- datu pārvaldības plāns (DPP): izveidot dokumentu, kas ietver visus datu pārvaldības aspektus. Daudzi finansētāji un institūcijas pieprasa DPP kā daļu no grantu pieteikumiem.
Rūpīgi veicot sākotnējo plānošanu, pētnieki var nodrošināt datu integritāti, pieejamību un ilgtermiņa izmantojamību, tādējādi padarot savus pētījumus uzticamākus un ietekmīgākus.
Datu vākšana ir process, kurā, izmantojot instrumentus vai citas metodes, tiek iegūta informācija par konkrētiem interesējošiem mainīgajiem. Datu vākšanas posms ir būtiska pētniecības datu pārvaldības fāze, jo tajā tiek iegūti dati, kas nepieciešami pētniecības mērķu sasniegšanai. Pareiza datu vākšana nodrošina to precizitāti, uzticamību un lietojamību analīzei un turpmākai izmantošanai.
Projektā var izmantot arī jau esošus datus. Detalizētāku informāciju skatīt datu dzīves cikla sadaļā “Atkārtota izmantošana un arhivēšana”.
Ir ļoti svarīgi īstenot kvalitātes kontroles pasākumus un pareizi dokumentēt datu vākšanas procedūras. Datus var pārvaldīt un dokumentēt to vākšanas laikā, izmantojot piemērotus rīkus. Elektroniskās laboratorijas piezīmju grāmatas (Electronic Lab Notebooks), elektroniskās datu vākšanas (Electronic Data Capture) sistēmas un laboratorijas informācijas pārvaldības sistēmas (Laboratory Information Management Systems) ir piemēroti rīki datu pārvaldībai un dokumentēšanai datu vākšanas posmā.
Datu vākšanas posma galvenie aspekti:
- datu vajadzību definēšana: identificēt pētniecības jautājumus un mērķus; noteikt nepieciešamo datu veidu un formātu (kvantitatīvi, kvalitatīvi, strukturēti, nestrukturēti). Strukturētajiem datiem tiek izmantots iepriekš noteikts formāts, savukārt nestrukturētiem datiem pirms analīzes ir nepieciešama papildu apstrāde;
- datu vākšanas metožu izvēle:
- primāro datu vākšana (jauni dati, ko pētnieki iegūst tieši): aptaujas, intervijas, fokusa grupas; eksperimenti un simulācijas; novērojumi un lauka darbi; sensoru dati vai reāllaika monitorings;
- sekundāro datu vākšana (esoši dati no citiem avotiem): valdības ziņojumi, datubāzes un repozitoriji; publicēti pētījumi, grāmatas un raksti; sociālo mediju un tīmekļa dati. Tomēr pirms sekundāro datu izmantošanas pētniekiem jānovērtē to ticamība, atbilstība un iespējamā pārformatēšanas nepieciešamība;
- datu vākšanas rīki un tehnoloģijas, kur manuālās metodes piedāvā elastību, bet digitālie un automatizētie rīki uzlabo efektivitāti un samazina cilvēku kļūdas:
- manuālie rīki: papīra veidlapas, piezīmju grāmatas, balss ieraksti;
- digitālie rīki: tiešsaistes aptaujas, datubāzes, elektroniskās laboratorijas piezīmju grāmatas;
- automatizētās metodes: tīmekļa izguve, lietojumprogrammu saskarnes, lietu interneta sensori;
- datu kvalitātes un integritātes nodrošināšana: samazināt kļūdas, izmantojot standartizētus datu vākšanas protokolus. Izmantot validācijas paņēmienus, piemēram, dublikātu pārbaudes, noviržu noteikšanu un konsekvences pārbaudes. Kvalitātes kontrole būtu jāpiemēro gan savākšanas vietā, gan vēlākos apstrādes posmos, lai saglabātu precizitāti;
- ētiskie apsvērumi un atbilstība normatīvajiem aktiem: iegūt nepieciešamos apstiprinājumus, piemēram, no institucionālās ētikas komitejas; nodrošināt informētu piekrišanu, ja dati tiek iegūti no cilvēkiem; ievērot datu aizsardzības regulas, piemēram, VDAR sensitīvu datu gadījumā; datu kopām, kas satur personu identificējošu informāciju (PII), vajadzības gadījumā jāpiemēro anonimizācijas vai pseidonimizācijas paņēmieni;
- datu dokumentēšana un metadatu izveide: reģistrēt informāciju par datu vākšanas metodēm, rīkiem, datumiem un iesaistītajiem pētniekiem; veidot metadatus, lai uzlabotu datu interpretāciju un turpmāko izmantošanu (skatīt arī https://www.lbtu.lv/lv/metadati);
- droša uzglabāšana un dublēšana: glabāt neapstrādātus datus drošās krātuvēs vai mākoņsistēmās; uzturēt rezerves kopijas, lai novērstu datu zudumu (skatīt arī https://www.lbtu.lv/lv/datu-deponesana).
Rūpīgi plānojot un īstenojot datu vākšanas posmu, pētnieki nodrošina, ka viņu dati ir precīzi, ētiski, labi dokumentēti un gatavi analīzei.
Datu apstrāde ietver datu organizēšanu, tīrīšanu, pārveidošanu un sagatavošanu analīzei. Šis posms nodrošina neapstrādātu datu pārvēršanu strukturētā un lietojamā formātā, vienlaikus saglabājot precizitāti un integritāti.
Datu apstrādes galvenie mērķi:
- pārveidot datus lasāmā formātā, nodrošinot tiem struktūru un formu, kas nepieciešama turpmākai analīzei;
- novērst kļūdainus vai zemas kvalitātes datus, lai izveidotu “tīru”, augstas kvalitātes datu kopu uzticamu rezultātu iegūšanai.
Lai sagatavotu datus analīzei, apstrāde var ietvert arī manuālas darbības, īpaši gadījumos, kad dati tiek importēti no jau esošiem avotiem, piemēram, atkārtoti izmantojot datus no cita projekta. Šīs darbības var ietvert:
- datu struktūras pielāgošanu, lai dažādas datu kopas varētu integrēt vienu ar otru;
- datu kodēšanas sistēmu vai ontoloģiju maiņu, lai nodrošinātu saskaņotību;
- datu filtrēšanu, saglabājot tikai ar projektu saistīto informāciju.
Efektīva datu apstrāde ir ļoti svarīga, lai nodrošinātu datu kvalitāti un izmantojamību analīzē.. Precīza datu apstrāde ir nepieciešama arī gadījumos, kad tiek apvienotas divas vai vairākas datu kopas. Pētījumu rezultātu reproducējamība ir atkarīga no katra datu apstrādes posma rūpīgas dokumentācijas. Pareizi veikta datu apstrāde uzlabo efektivitāti, uzlabo darba organizāciju un atvieglo precīzu analīzi.
Datu apstrādes posma galvenās sastāvdaļas:
- datu tīrīšana un validācija: kļūdu, neatbilstību vai trūkstošo vērtību atklāšana un labošana; formātu standartizēšana un dublētu vai neatbilstošu datu noņemšana; datu precizitātes un pilnīguma pārbaude;
- datu pārveidošana: neapstrādātu datu konvertēšana strukturētā formātā, piemēram, no nestrukturēta teksta uz tabulām; datu normalizēšana, apkopošana vai klasifikācija atbilstoši pētniecības vajadzībām; kodēšanas vai klasifikācijas shēmu piemērošana kvalitatīviem datiem;
- datu integrācija: datu kopu apvienošana no dažādiem avotiem, vienlaikus nodrošinot konsekvenci; mainīgo saskaņošana un formātu standartizēšana saderībai;
- datu anonimizācija un drošības pasākumi: nepieciešamības gadījumā personu identificējošas informācijas (PII) noņemšana; šifrēšanas vai piekļuves kontroles izmantošana sensitīvu datu aizsardzībai;
- metadatu ģenerēšana: apstrādes soļu dokumentēšana pārredzamībai un reproducējamībai;
- starpposmu glabāšana un dublēšana: apstrādāto datu droša uzglabāšana, lai novērstu to zudumu; datu aizsardzības rezerves stratēģijas ieviešana.
Pareizi pārvaldot datu apstrādes posmu, pētnieki nodrošina, ka viņu dati ir tīri, uzticami un gatavi analīzei, tādējādi uzlabojot pētījumu kvalitāti un reproducējamību.
Datu analīze ir būtisks pētniecības datu dzīves cikla posms, kurā apstrādātie dati tiek pārbaudīti, interpretēti un pārveidoti jēgpilnās atziņās. Šis posms ietver statistisko vai kvalitatīvo metožu izmantošanu, lai identificētu modeļus, datu sakarības un izdarītu secinājumus, kas atbalsta pētniecības mērķus.
Datu analīze ir posms, kurā tiek radīta jauna informācija un zināšanas. Tā kā datu analīzes rezultāti būtiski ietekmē pētniecības atziņas, ir svarīgi, lai pielietotās analīzes metodes atbilstu FAIR principiem. Turklāt ir svarīgi, lai citi pētnieki varētu atkārtot analīzes procesu, tādējādi nodrošinot pētījuma reproducējamību.
Pieaugot datu apjomam un pētījumu starpdisciplinaritātei, rodas nepieciešamība pēc speciālistiem dažādās jomās. Pirms datu analīzes uzsākšanas atkarībā no pētījuma vajadzībām ir jāizvēlas piemērota skaitļošanas vide, piemēram, mākoņskaitļošana vai lokālie serveri. Tāpat jāizvēlas atbilstoši analīzes rīki – tie var būt tiešsaistes platformas vai lokāli instalēta programmatūra, atkarībā no lietotāja pieredzes un prasībām.
Ir svarīgi rūpīgi dokumentēt katru veikto darbību datu analīzes procesā. Tas ietver skaitļošanas vidi, izmantotās metodes, parametru iestatījumus un programmatūras versijas. Manuālas manipulācijas ar datiem ir jāsamazina vai rūpīgi jādokumentē, lai nodrošinātu reproducējamību..
Ja datu analīzi veic kopīgi pētnieku grupā, jānodrošina, lai visiem iesaistītajiem būtu piekļuve nepieciešamajiem datiem un rīkiem. Šo procesu var atvieglot, izveidojot virtuālās pētniecības vides.
Lai nodrošinātu FAIR principu ievērošanu (skatīt arī https://www.lbtu.lv/lv/fair-principi-un-dati), ieteicams publicēt gan datu kopas, gan analīzes procesu.
Datu analīzes posma galvenās sastāvdaļas:
- analītisko metožu izvēle: atlasīt piemērotas analīzes metodes (statistiskā analīze, mašīnmācīšanās, kvalitatīvā kodēšana), nodrošinot to atbilstību pētniecības jautājumiem un datu tipiem;
- statistisko un datorizēto rīku izmantošana: lai veiktu analīzi, izmantot programmatūru, piemēram, R, Python, SPSS, NVivo, MATLAB; piemērot aprakstošo statistiku vai tendenču analīzi;
- izpētes datu analīze: identificēt modeļus, korelācijas un anomālijas datu kopā; izmantot datu vizualizācijas paņēmienus (grafikus, diagrammas, siltumkartes), lai apkopotu iegūtos rezultātus;
- hipotēžu pārbaude un modelēšana: pārbaudīt pētniecības hipotēzes, izmantojot atbilstošus statistikas testus, piemēram, t-testus, ANOVA, regresijas analīzi; izstrādāt prognozējošus vai skaidrojošus modeļus;
- rezultātu interpretācija: izdarīt jēgpilnus secinājumus, salīdzinot rezultātus ar citiem informācijas avotiem vai teorētiskajiem modeļiem;
- reproducējamības un caurskatāmības nodrošināšana: dokumentēt analīzes darbplūsmu, tostarp kodu, formulas un lēmumu pieņemšanas soļus; izmantot versiju kontroles sistēmas, piemēram, GitHub vai OSF izmaiņu izsekošanai;
- ētiskie apsvērumi: nodrošināt objektīvu rezultātu interpretāciju; saglabāt datu konfidencialitāti un integritāti.
Efektīvi pārvaldot datu analīzes posmu, pētnieki var radīt ticamus un pārbaudāmus secinājumus, veicinot augstas kvalitātes un reproducējamus pētniecības rezultātus.
Datu uzglabāšanas un saglabāšanas posms nodrošina, ka dati ilgtermiņā paliek pieejami, droši un lietojami. Pareiza šī posma veikšana ļauj nodrošināt pētījumu validāciju, atkārtotu izmantošanu un atbilstību institucionālajām un finansētāju prasībām.
Datu saglabāšana ir nepieciešama vairāku iemeslu dēļ:
- nodrošināt datu reproducējamību un validāciju pat vairākus gadus pēc pētījuma beigām;
- ļaut atkārtoti izmantot datus nākotnē, piemēram, izglītībā vai citos pētījumos;
- ievērot finansētāju, izdevēju un institūciju prasības par noteiktu datu uzglabāšanas periodu;
- saglabāt svarīgu informāciju, kas var būt būtiska uzņēmumam, valstij, videi vai sabiedrībai kopumā.
Datu saglabāšana ir profesionāls un ilgtermiņa process, kas prasa atbilstošu plānošanu, normatīvo aktu ievērošanu, resursus (cilvēkresursus, finanses, laiku) un tehnoloģijas. Digitālo datu saglabāšanai nepieciešamas ilgtermiņa datu krātuves, kurās tiek izsekota informācijas integritāte.
Ieteicamie datu saglabāšanas risinājumi:
- sazinieties ar savas institūcijas datu centru, bibliotēku vai IT nodaļu;
- noskaidrojiet valstī piedāvātos pakalpojumus datu arhivēšanai;
- atkarībā no datu veida izvēlieties uzticamus repozitorijus, piemēram, Zenodo, Dryad vai institucionālos.
Nosacījumi datu sagatavošanai ilgtermiņa saglabāšanai:
- izvairieties no mainīgiem vai īslaicīgiem datiem;
- pārliecinieties, ka dokumentācija ir skaidra un pašsaprotama;
- nodrošiniet informāciju par datu izcelsmi;
- norādiet licencēšanas nosacījumus, lai definētu atkārtotas izmantošanas iespējas;
- datu apzīmējumos izmantojiet nozaru standartus vai vārdnīcas;
- izmantojiet atvērtus, standartizētus failu formātus, piemēram, CSV, XML, PDF/A, TIFF.
Ja nepieciešams saglabāt nedigitalizētus datus, piemēram, papīra dokumentus, apsveriet to digitalizēšanu vai konsultējieties ar institūcijas datu pārvaldības speciālistiem.
Datu uzglabāšanas un saglabāšanas posma galvenās sastāvdaļas:
- uzglabāšanas risinājumu izvēle: izvēlēties piemērotas glabāšanas iespējas (lokālos serverus, mākoņkrātuves, institucionālos repozitorijus);
- datu organizēšana un failu pārvaldība: ievērot strukturētu failu nosaukšanas un mapju organizēšanas sistēmu un izmantot standartizētus formātus ilgtermiņa pieejamībai, piemēram, CSV, XML, PDF/A;
- datu drošības pasākumu īstenošana: pielietot šifrēšanu, piekļuves kontroli un autentifikācijas protokolus, nodrošināt atbilstību datu aizsardzības normatīviem, piemēram, VDAR;
- datu rezerves kopiju veidošana: izmantot automatizētas dublēšanas stratēģijas, piemēram, ikdienas, iknedēļas u.tml. kopijas; uzglabāt rezerves kopijas vairākās vietās, lai samazinātu zuduma risku;
- metadatu un dokumentācijas saglabāšana: uzturēt visaptverošus metadatus, lai aprakstītu datu saturu, struktūru un kontekstu. Dokumentācijā iekļaut informāciju par failu formātiem, mainīgajiem un metodoloģijām;
- ilgtermiņa saglabāšanas stratēģijas: izmantot digitālās krātuves. Laika gaitā migrēt datus uz jaunākiem formātiem, lai novērstu tehnoloģisko novecošanos;
- datu pieejamības nodrošināšana: definēt skaidru datu koplietošanas politiku un piekļuves tiesības. Piešķirt pastāvīgos identifikatorus, piemēram, DOI, lai nodrošinātu citējamību un izgūšanu.
Efektīvi pārvaldot datu uzglabāšanu un saglabāšanu, pētnieki nodrošina, ka vērtīgas datu kopas paliek drošas, pieejamas un atkārtoti izmantojamas nākotnes pētījumiem, verifikācijai vai validācijai.
Datu kopīgošanas un publicēšanas posms ir būtisks, jo tas nodrošina, ka pētījuma dati tiek padarīti pieejami citiem pētniekiem, institūcijām un sabiedrībai, lai tos varētu validēt, atkārtoti izmantot pētījumos. Pareiza datu koplietošana un publicēšana uzlabo pētījumu caurspīdīgumu, reproducējamību un ietekmi.
Datus var kopīgot publiski, padarot tos pieejamus pasaules zinātniskajai sabiedrībai un sabiedrībai kopumā, vai arī kopīgot tos ar saviem sadarbības partneriem kopīga pētniecības projekta ietvaros.
Ir svarīgi saprast, ka datu koplietošana nav līdzvērtīga publiskiem vai atvērtiem datiem. Datiem var būt slēgta vai ierobežota piekļuve. Tāpat publicēt zinātnisku rakstu žurnālā nav tas pats, kas publicēt datus. Datu publicēšana attiecas uz tādiem materiāliem kā izejas novērojumi, mērījumi, analīzes darbplūsmas, kods utt.
Ideālā gadījumā datu kopīgošanai vajadzētu notikt tajā brīdī, kad tiek publicēts zinātniskais raksts, kas balstās uz attiecīgajiem datiem. Daudzas organizācijas un zinātniskie žurnāli pieprasa datu kopīgošanu, izņemot gadījumus, kad tam ir pamatoti ētiski, juridiski vai līgumiski ierobežojumi.
Eiropas Pētniecības integritātes rīcības kodekss iesaka vadīties pēc principa “cik vien iespējams atklāti, cik vien nepieciešams slēgti”. Pat, ja dati nav pilnībā atvērti, ieteicams padarīt to metadatus publiskus, lai nodrošinātu to izmantošanas iespējas nākotnē.
Datu piekļuves veidi:
- atvērtā piekļuve (open access): dati ir publiski pieejami ikvienam bez ierobežojumiem;
- reģistrētā piekļuve (registered access): lietotājiem pirms datu izmantošanas ir jāreģistrējas un jāpiekrīt repozitorija lietošanas noteikumiem. Šādi var izsekot, kas izmanto datus;
- datu piekļuves komitejas vai kontrolēta piekļuve (controlled access): pieeju datiem piešķir speciāla komiteja, kas izvērtē pieprasījumus pēc noteiktiem kritērijiem, piemēram, pētniecības tēma, atļautie ģeogrāfiskais reģioni, atļautie saņēmēji utt.;
- piekļuve pēc pieprasījuma (nav ieteicama): šajā gadījumā datu īpašniekam (ar datu kopām saistītajos metadatos vai dokumentācijā ir jāiekļauj datu īpašnieka kontaktinformācija) jāizlemj par katru pieprasījumu atsevišķi. Šāda pieeja var radīt aizkavējumus datu izmantošanā un slodzi datu pārvaldībā.
Datu kopīgošanas un publicēšanas posma galvenās sastāvdaļas:
- datu repozitorija izvēle: izvēlēties piemērotu repozitoriju (piemēram, Zenodo, Dryad, Figshare vai institucionālo) un pārliecināties, ka tas atbilst finansētāju un institucionālajām prasībām;
- atvērtās zinātnes principu piemērošana: ievērot FAIR principus (atrodams, pieejams, sadarbspējīgs, atkārtoti izmantojams). Ja iespējams, izmantot atvērtās piekļuves platformas, lai maksimāli palielinātu datu sasniedzamību;
- datu licencēšana un piekļuves kontrole: definēt datu izmantošanas atļaujas ar licencēm, piemēram, Creative Commons (CC BY, CC0) un definēt piekļuves līmeņus (atvērti, ierobežoti, embargo), pamatojoties uz ētiskiem vai juridiskiem apsvērumiem;
- metadatu un dokumentācijas publicēšana: nodrošināt skaidrus metadatus, lai aprakstītu datu kopu, piemēram, failu formātus, vākšanas metodes, mainīgos utt., pievienot README failus, kodu grāmatas un kontekstuālo informāciju, lai nodrošinātu datu lietojamību;
- patstāvīgo identifikatoru (PID) piešķiršana: izmantot DOI vai citus identifikatorus, lai nodrošinātu datu kopu citējamību un izsekojamību. Saistīt datu kopas ar attiecīgajiem zinātniskajiem rakstiem, lai palielinātu to ietekmi;
- atbilstība ētiskajām un juridiskajām vadlīnijām: nodrošināt privātuma aizsardzību un atbilstību normatīvajiem aktiem, piemēram, VDAR. Ja nepieciešams, anonimizēt datus, lai aizsargātu sensitīvu informāciju;
- atkārtotas izmantošanas un citēšanas veicināšana: popularizēt datus zinātniskajos rakstos un konferenču prezentācijās. Veicināt pareizu data kopu citēšanu akadēmiskajās publikācijās.
Efektīva datu kopīgošana un publicēšana uzlabo pētniecības caurspīdīgumu, uzticamību un ilgtspēju. Tā nodrošina, ka pētnieku darbs kļūst redzamāks, ietekmīgāks un sniedz lielāku ieguldījumu zinātnes attīstībā.
Datu atkārtotas izmantošanas un arhivēšanas posms nodrošina, ka dati ilgstoši ir pieejami pārbaudei un turpmākai izmantošanai. Pareiza arhivēšana saglabā datu integritāti, savukārt atkārtota izmantošana veicina efektivitāti, inovācijas un sadarbību pētniecībā.
Datu atkārtota izmantošana nozīmē to pielietošanu mērķiem, kas atšķiras no tiem, kuriem tie sākotnēji tika vākti, piemēram, jaunu zinātnisko atziņu gūšanai vai metaanalīzēm. Datu atkārtota izmantošana ir būtiska zinātnē, jo tā ļauj dažādiem pētniekiem neatkarīgi veikt atklājumus, balstoties uz tiem pašiem datiem. Viens no FAIR principu būtiskākajiem aspektiem ir datu atkārtotas izmantojamības nodrošināšana.
Esošo datu atkārtota izmantošana ļauj:
- iegūt atsauces datus savam pētījumam;
- izvairīties no nevajadzīgu jaunu eksperimentu veikšanas;
- palielināt pētījumu robustumu, apvienojot dažādu paraugu vai metožu rezultātus;
- gūt jaunus ieskatus, savienojot un metaanalizējot datu kopas.
Lai atkārtoti izmantotu esošus datus, ir jāpārliecinās, vai ir izpildītas šādas prasības:
- izpētīt dažādus datu avotus, kurus var izmantot atkārtoti. Jāizvēlas uzticami avoti, piemēram, zinātniskie datu repozitoriji (Zenodo, Dryad, Figshare), datu žurnāli vai tieša saziņa ar autoru;
- pārliecināties, vai dati ir licencēti un vai licence atļauj to plānoto atkārtoto izmantošanu. Creative Commons (CC BY, CC0) licences parasti ir piemērotas datu kopīgošanai un atkārtotai izmantošanai;
- pārbaudīt, vai ir pieejams pietiekami daudz metadatu. Lai gan dažus datu tipus, piemēram, genoma datus, var viegli izmantot atkārtoti, citiem, var būt nepieciešams daudz metadatu, lai tos interpretētu un atkārtoti izmantotu;
- pārbaudīt datu kvalitāti, t.i., noteikt, vai tie ir apkopoti, no uzticama avota un vai tie atbilst nozares vai citiem standartiem;
- pārliecināties, ka datu izmantošana atbilst ētikas prasībām un pētījuma vadlīnijām;
- ja atkārtoti izmanto datus, kas tiek atjaunināti, jāpiefiksē, kuru versiju izmanto. Jāapsver, kā izmaiņas var ietekmēt analīzi un secinājumus;
- ja datu kopai ir pastāvīgs identifikators, piemēram, DOI, tas jānorāda publikācijā, lai pareizi atsauktos uz avotu.
Datu atkārtotas izmantošanas un arhivēšanas posma galvenie elementi:
- datu pieejamības nodrošināšana: glabāt datus uzticamos repozitorijos, piešķirt pastāvīgos identifikatorus, lai nodrošinātu vieglu citēšanu un izguvi;
- datu atklāšanas veicināšana: publicēt datus atvērtās piekļuves datubāzēs un zinātniskajos tīklos, izmantot standartizētas metadatu shēmas, piemēram, Dublin Core vai DataCite, lai uzlabotu datu kopas atklājamību un indeksēšanu;
- datu licencēšana un piekļuves kontrole: izmantot Creative Commons (CC BY, CC0) vai citus licencēšanas modeļus, lai skaidri definētu datu atkārtotas izmantošanas nosacījumus. Ja nepieciešams, piemērot ierobežojumus, piemēram, ētiskie apsvērumi, embargo periodi;
- datu arhivēšana ilgtermiņa saglabāšanai: uzglabāt datus nepatentētos failu formātos, piemēram, CSV, XML, PDF/A, lai nodrošinātu ilgtspējību. Nodrošināt periodisku datu migrāciju, lai novērstu tehnoloģisko novecošanos;
- datu integritātes un versiju pārvaldība: ieviest versiju kontroli, lai sekotu izmaiņām un novērstu neskaidrības. Izmantot kontrolsummas (checksum verification), kā aizsarglīdzekli pret datu sabojāšanu vai iejaukšanos;
- sekundāro pētījumu un sadarbības veicināšana: veicināt pētnieku sadarbību, lai dati tiktu izmantoti dažādās nozarēs. Popularizēt datu atkārtotu izmantošanu, lai samazinātu resursu izšķērdēšanu un veicinātu inovācijas.
Efektīva datu atkārtota izmantošana un arhivēšana palielina datu vērtību un ilgtspēju. Tā nodrošina, ka dati paliek pieejami un izmantojami nākotnes pētījumiem, tiek veicināta zinātniskā sadarbība un reproducējamība, tiek optimizēti resursi un izvairīšanās no liekiem eksperimentiem.
Bossaller J., Million A. J. (2023). The research data life cycle, legacy data, and dilemmas in research data management. Journal of the Association for Information Science and Technology, Vol. 74, pp. 701–706. DOI: 10.1002/asi.24645
Elixir (2024). Data life cycle. [tiešsaiste] [skatīts 17/02/2025]. Pieejams: https://rdmkit.elixir-europe.org/data_life_cycle (CC-BY)
Kvale L. H., Darch P. (2022). Privacy protection throughout the research data life cycle. Information Research, Vol. 27 (3), pp. 1–26. DOI: 10.47989/IRPAPER938
Shuliang L. (2024). Information Management. Springer; 506 p. DOI: 10.1007/978-3-031-64359-0
Zhang J., Symons J., Agapow P., Teo J. T., Paxton C. A., Abdi J., Mattie H., Davie C., Torres A. Z., Folarin A., Sood H., Celi L. A., Halamka J., Eapen S., Budhdeo S. (2022). Best practices in the real-world data life cycle. PLOS Digital Health, Vol. 1, pp. 1–14. DOI: 10.1371/journal.pdig.0000003